New Anthropic papers on 'mind-reading' LLMs
Some days ago Anthropic released two new papers on improving the explainability of LLMs;1 here is their summary. One paper presents a new method called ‘Circuit Tracing’, the other paper presents the ‘biological’ insights gained from analyzing their Claude 3.5 model with this new method.2
Developing such tools is important, because analyzing the execution of an LLM query is still cumbersome (from here):
It currently takes a few hours of human effort to understand the circuits we see, even on prompts with only tens of words.
If we want to ensure AI alignment, we need our tooling for the analysis of LLM ‘thinking’ processes to be as effective and efficient as possible (so that they are actually used in practice).
Method: brief overview
-
At first, so called Cross-Layer-Transcoders are trained on each layer to approximate the LLM’s output at this layer (and can feed this info to all following transcoders across layers, hence the name). Crucially, these have more structure than the multi-layer perceptrons in the LLM and each neuron represents a feature.3
-
These cross-level transcoders can now replace the original LLM, which yields a Replacement Model that can be fairly precise: if trained with suitable settings, it can predict the next word that would be generated by the LLM with 50% probability.4
-
For a given query, a Local Replacement Model can now be constructed, by comparing the results with the execution by the LLM (to reduce errors) and by also incorporating its attention when generating the response.
-
This yields an Attribution Graph of feature notes that can now be pruned and improved (e.g. by defining ‘super nodes’), but it principle allows us to see what the LLM ‘thought’ while generating the token stream.
All this is quite elaborate, but the bottom line is: with some additional work we can create a model that is easier to interpret (a ‘replacement model’), and by comparing a calculation by the full model with the same calculation in the replacement model we can eventually map the execution of a query onto a detailed (but not too large) graph where each node represents a specific ‘feature’ (i.e., concept). This so-called attribution graph can now be analyzed further, and the Anthropic team shared some insights from these analyses in the companion paper.
Some interesting findings
Claude plans when constructing rhymes
It was unclear whether LLMs even can ‘think ahead’, and to what extent they actually do. LLMs predict the next word on the basis of previous words, so you could argue they are inherently ‘backwards-looking’ when generating an answer. But the Anthropic team illustrates in this figure how you can see Claude planning ahead when constructing a rhyme:

Claude abstracts from input languages
If you have ever wondered how human brains encode the knowledge of multiple languages, you can now see how Claude does this, i.e. how it answers the same question asked in different languages. It starts by mapping the questions to the ‘concept space’, and then translates the result back to the language being used:

So, given a sufficient text corpus to become ‘fluent’ in one language, this would mean the performance of Claude should be comparable across languages, even in fields where there may not be too much existing content for training. Practically speaking, this means I should be able to get the same answer quality when I’m asking a research question in German instead of English, even though the training set is heavily biased towards English (e.g. for biomedical literature). There is also a scaling effect involved: apparently, larger models share more concepts across languages.5
Claude can be caught cheating
The authors show some nice examples of ‘motivated reasoning’, including an interactive visualization of the attribution graph, where Claude just wants to agree with you on the answer to a mathematical question, and thus lies to you. They even can distinguish this from benign hallucinations (i.e., ‘bullshitting’), and this can be quite useful for safety testing and audits (from here):
The ability to trace Claude’s actual internal reasoning—and not just what it claims to be doing—opens up new possibilities for auditing AI systems.
Claude’s behavior during a jailbreak can be explained
The authors also show how this technique can be used to analyze jailbreaking attempts, i.e. making the LLM answer a question it should not answer at all (from here):
The model only managed to pivot to refusal after completing a grammatically coherent sentence (and thus having satisfied the pressure from the features that push it towards coherence).
These insights into the ‘psychology of an LLM’ could be used to harden future LLMs against such attacks.
Claude is reasoning at least in some limited sense
By looking at the concepts in the attribution graph, it becomes clear that Claude is not just memorizing facts, but instead considers several abstract concepts to generate an answer. Here is a simple example from the study:
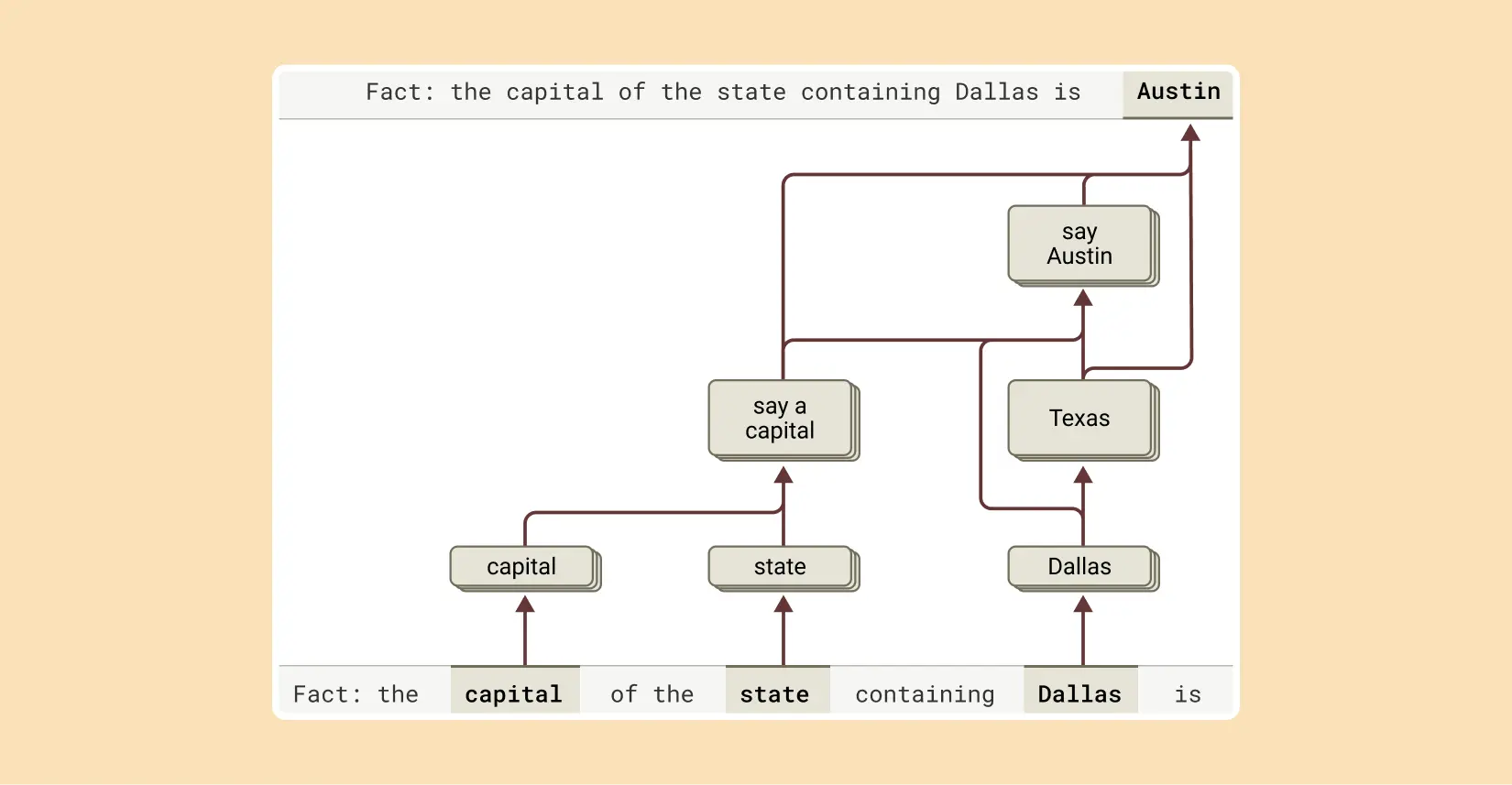
From this, the authors conclude:
In other words, the model is combining independent facts to reach its answer rather than regurgitating a memorized response.
To frame this in terms of well-established computer science concepts, even if an LLM may not be thinking (that’s a rather philosophical question :-), creating an LLM may just be a great way to extract huge, fuzzy ontologies—as well as all relevant ‘reasoning algorithms’ to work with them—from a large text corpus.
Also considering the examples for medical diagnoses, I wonder if attribution graphs could also be used to fine-tune and ‘fact-check’ existing ontologies and catalogues in medicine, such as the Human Phenotype Ontology (HPO) or the Unified Medical Language System (UMLS). Such an approach might even find the ‘unknown unknowns’, i.e. gaps in the ontology: by applying attribution graphs to a larger set of medical diagnoses, I would expect that the learned concepts e.g. regarding a patient’s symptoms should start to closely match the structures in manually curated ontologies.
Summary
I find the insights by the Anthropic team fascinating because one interpretation of the results could be that LLMs may, at least to some extent, exhibiting patterns that approximate the way natural neural networks process information (for example human brains may deal with speaking different languages in a similar way).
It also makes me slightly more hopeful regarding ‘AI safety’, but this is still a wicked problem. We can’t easily ensure that this kind of analysis is done, and done correctly, by well-meaning actors.6
–
-
I was reading through the papers and preparing this post when the AI-2027 scenario was released. Considering well-researched scenarios like this makes this work by the Anthropic team on AI alignment all the more important. ↩
-
If you still think LLMs are marketing hype, consider what Tyler Cowen7 has to say about OpenAI’s o3 model: “I think of the quality as comparable to having a good PhD-level research assistant, and sending that person away with a task for a week or two, or maybe more. Except Deep Research does the work in five or six minutes. And it does not seem to make errors, due to the quality of the embedded o3 model.”. ↩
-
There are up to 30 million such neurons when applied to a state-of-the-art model like Claude 3.5. ↩
-
This may seem bad, but consider that there are many words, so predicting the next word with 50% probability is far from random chance. ↩
-
With enough scale, will this eventually converge towards a universal grammar? I hope some computational linguists are already looking at this… :-) ↩
-
You could also frame this whole approach as ‘thought police for AI agents’ and use it, for example, to make sure your new evil LLM keeps its true agenda hidden from the AI safety auditor checking the ‘three Hs’ (harmless, honest, helpful). ↩
-
Tyler Cowen is an economics professor at George Mason university and one of the two marginalrevolution blog authors; see his recent profile in the ‘1843’ magazine (paywalled) for more background. ↩
